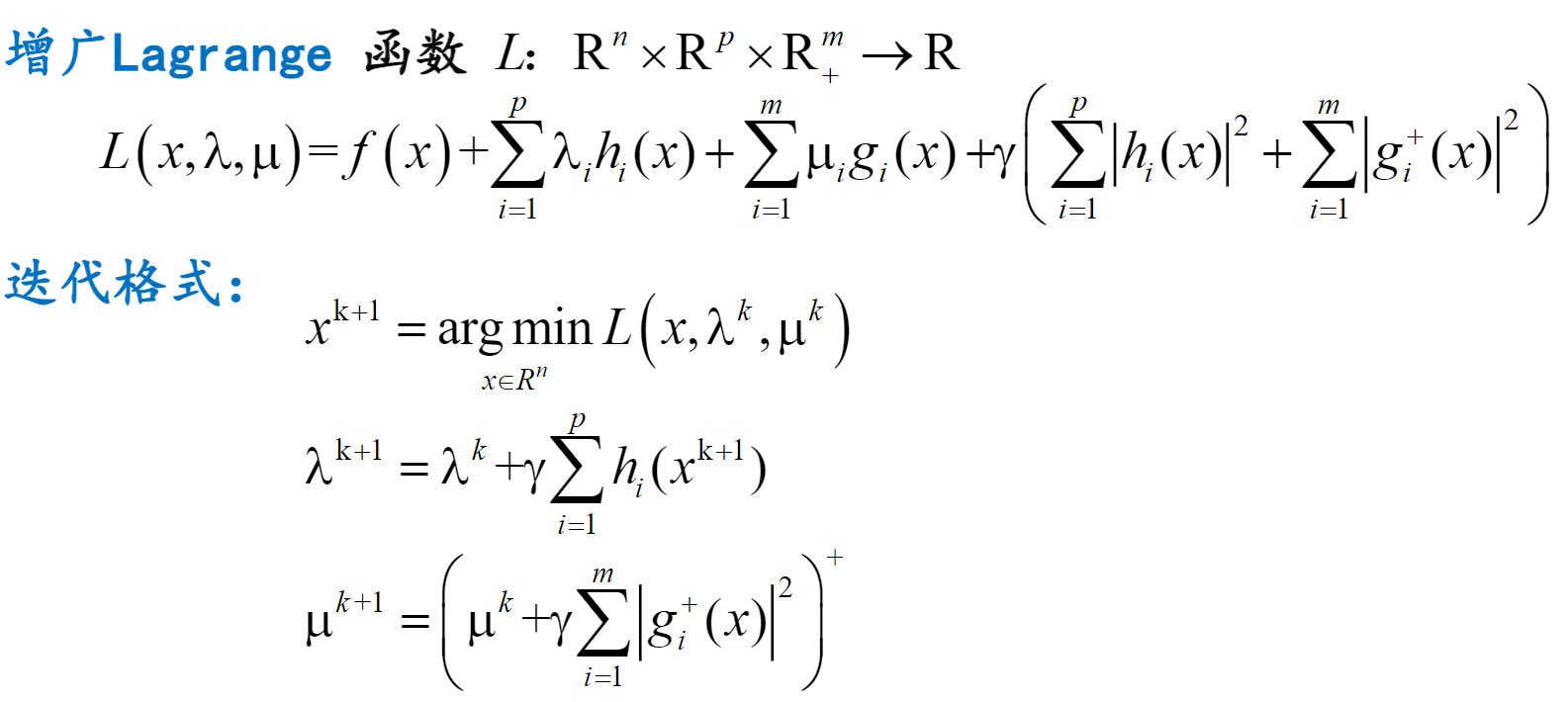最优化算法速通 - 约束优化
07 December 2022 |
duanyll | Tags:
最优化
等式约束
\[\begin{aligned} \mathrm{minimize}\;\;&f(x)\\ \mathrm{subject\ to}\;\;&h_i(x)=0,&i=1,\cdots,m\\ \end{aligned}\]- 正则点: 对于满足等式约束的点 $x^*$, 梯度向量 $\nabla h_{1}(x^{\ast}),\ldots,\nabla h_{m}(x^{\ast})$ 线性无关.
- $x^$ 是正则点 $\lrArr \operatorname{rank}Dh(x^)=m$
- 曲面 $S={x\in R^{n}\colon h_{1}(x){=}0,\ldots,h_{m}(x){=}0}$, 若 $S$ 上所有点都是正则点, 则维数为 $n-m$
- 切线空间 $T(x^{\ast})\;=\;\left{:y:D h(x^{\ast})y=0\right}$, 即 $Dh(x^*)$ 的零空间.
- 正则点的切空间维数是 $n-m$
- 切平面 $T P(x^{})=T(x^{})+x^{}={x+x^{}:x\in T(a x^{*})}$
- 法线空间 $N(x^{})={x\in\mathbb{R}^{}:x=D h(x^{*})^{\top}z,\ z\in\mathbb{R}^{m}}$
- $N(\alpha^{})={\mathcal{R} }\left(D h(x^{})^{\top}\right)={\mathrm{span} }[\nabla h_{1}(x^{}),\cdots,\nabla h_{m}(x^{})]$
- 正则点的法线空间的维数是 $m$
- 法平面 $N P(x^{})=N(x^{})+x^{}={x+x^{}\in\mathbb{R}^{n}:x\in N(x^{*})}$
- 切线空间和法线空间互为正交补
Lagrange 条件
若 $x^$ 是极大点则满足 $\nabla f(x^)$ 和 $\nabla h(x^*)$ 平行, 即
\[\begin{aligned} \nabla f(x^{*})+\lambda^{*}\nabla h(x^{*})&=0\\ h(x^*)&=0 \end{aligned}\]Lagrange 定理: 若 $x^$ 是正则点, 则 $\exist \lambda^\in\R^n$, 使得
\[D f(x^{*})+\lambda^{*\top}D h(x^{*})=0^\top\]是局部极小点的必要条件
Lagrange函数 $l:\R^n\times\R^m\to\R$
\[l(x,\lambda)= f(x)+\lambda^{\mathsf{T} }h(x)\]若 $x^$ 是极值点, 则 $\exists\lambda^$, 满足 $D l(x^{},\lambda^{})=0^{\mathsf{T} }$. Lagrange 定理的必要条件等价于将 Lagrange 函数视为无约束优化问题得到的一阶必要条件.
Lagrange 函数关于 $x$ 的 Hessian 矩阵:
\[[\lambda H(x)]=\lambda_{1}H_{1}(x)+\cdot\cdot\cdot+\lambda_{m}H_{m}(x)\\ {L}(x,\lambda)={F}(x)+[\lambda{H}(x)]\]- 二阶必要条件: $\forall y\in T(x^),y^\top L(x^,\lambda^*)y\geq0$
- 二阶充分条件: $\forall y\in T(x^),y^\top L(x^,\lambda^*)y>0$
二次规划
\[\mathrm{maximize}\;\frac{x^\top Qx}{x^\top Px}\]等价于
\[\begin{aligned} \mathrm{minimize}\;\;&x^\top Qx\\ \mathrm{subject\ to}\;\;&x^\top Px=1 \end{aligned}\]二次规划标准型
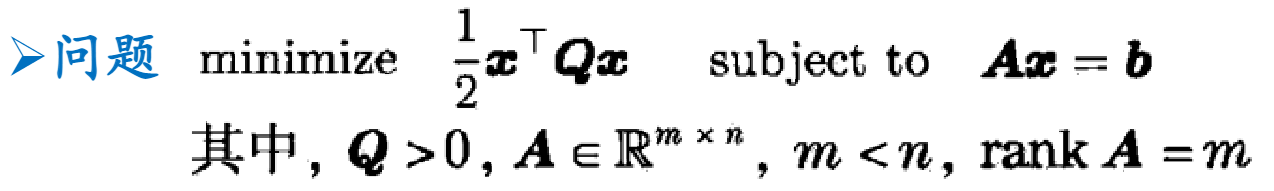
Lagrange 函数
\[l(x,\lambda)={\frac{1}{2} }x^{\top}Q x+\lambda^{\top}(b-A x)\]Lagrange 条件
\[D_{x}l(x^{*},\lambda^{*})=x^{*\top}Q-\lambda^{*\top}A=0^{\mathsf{T} }\\ Ax=b\]解得
\[\begin{array}{l l}{ { x^{*}=Q^{-1}A^{\top}(A Q^{-1}A^{\top})^{-1}b} }\\ { {\lambda^{*}=(A Q^{-1}A^{\top})^{-1}b} }\end{array}\]一定满足二阶充分条件.
不等式约束
\[\begin{aligned} \mathrm{minimize}\;\;&f(x)\\ \mathrm{subject\ to}\;\;&h_i(x)=0,&i=1,\cdots,m\\ &g_j(x)\leq0,&j=1,\cdots,p \end{aligned}\]- 积极约束, 非积极约束: 不等式是否取等
- 正则点除了考虑等式约束线性无关, 不等式约束梯度也要线性无关.
KKT 条件
设 $x^$ 是正则点和局部极小点, 则 $\exist\lambda^\in\R^m,\mu^*\in\R^p$, 使得
- 原始可行性: $h(x^)=0, g(x^)\leq0$
- 对偶可行性: $\mu^*\geq0$
- 原始最优性: $D f(x^{})+\lambda^{\top}D h(x^{})+\mu^{\top}D g(x^{*})=0^{\top}$
- 互补松弛条件: $\mu^{\top}g(x^{})=0$
二阶条件
\[\begin{aligned} [\lambda H(x)]&=\lambda_{1}H_{1}(x)+\cdot\cdot\cdot+\lambda_{m}H_{m}(x)\\ [\mu G(x)]&=\mu_{1}G_{1}(x)+\cdot\cdot\cdot+\mu_{p}G_{p}(x)\\ L(x,\lambda,\mu)&=F(x)+[\lambda H(x)]+[\mu G(x)] \end{aligned}\]起作用约束构成曲面的切空间
\[T(x^{*})=\{y\in\mathbb{R}^{n}:D h(x^{*})y=0,\ D g_{j}(x^{*})y=0,\ j\in J(x^{*})\}\]- 二阶必要条件: $\forall y\in T(x^{}), y^{\textsf{T} }L(x^{},\ \lambda^{},\mu^{})y\geq0$
- 二阶充分条件: $\forall y\in T(x^{}), y^{\textsf{T} }L(x^{},\ \lambda^{},\mu^{})y>0$
对偶问题
原问题 Lagrange 函数:
\[L(x,u,v)=f(x)-G(x)^\top u-H(x)^\top v\]鞍点 $(x^,u^,v^*)$ 是 Lagrange 函数关于 $x$ 的极小值点, 关于 $u,v$ 的极大值点
\[L(x^{*},u,v)\leqslant L(x^{*},u^{*},v^{*})\leqslant L(x,u^{*},v^{*}).\]原问题:
\[\begin{aligned} \operatorname*{min}\{f(x)\mid G(x)>0,H(x)=0\} &\lrArr \max_{u\geq0,v}L(x,u,v)= \begin{cases} \infty, &x\notin \Omega\\ f(x), &x\in \Omega \end{cases}\\ &\lrArr\operatorname*{min}_{x\in\mathbb{R}^{n} }\operatorname*{max}_{u\geq0,v}L(x,u,v) \end{aligned}\]对偶问题:
\[\operatorname*{max}_{u\geq0,v}\operatorname*{min}_{x\in\mathbb{R}^{n} }L(x,u,v)\]注意到对偶问题的内层 $\operatorname*{min}_{x\in\mathbb{R}^{n} }L(x,u,v)$ 是关于 $x$ 的无约束优化问题, 目标函数是凹函数
\[\theta(u,v)=\operatorname*{min}\{L(x,u,v)\mid x\in\mathbb{R}^{n}\}\]弱对偶定理: $x_0$ 是原问题可行解, $(u_0,v_0)$ 是对偶问题可行解, 则
\[f(x_{0})\geqslant\theta(u_{0},v_{0})\]即
\[\operatorname*{min}_{x\in\mathbb{R}^{n} }\operatorname*{max}_{u\geq0,v}L(x,u,v)\geq\operatorname*{max}_{u\geq0,v}\operatorname*{min}_{x\in\mathbb{R}^{n} }L(x,u,v)\]对偶问题的解是原问题的解的下界.
强对偶定理: 上式取等 $\lrArr$ Lagrange 函数存在鞍点 $(x^,u^,v^*)$
求解方法
投影方法
希望使无约束优化的迭代格式 $x^{(k+1)}=x^{(k)}+\alpha_{k}d^{(k)}$ 能够满足约束条件 $x\in\Omega$
投影: 设 $\Omega\in\R^n$ 是非空闭凸集, 任意 $x\in\R^n$ 在 $\Omega$ 上的投影为
\[\Pi[x]=\argmin_{x\in\Omega}\|z-x\|\]- $\Omega$ 是非空闭凸集, 投影存在且唯一
- $\forall z\in\Omega, (x-\Pi[x])^\top(z-\Pi[x])\leq0$
- 当且仅当 $\Omega$ 是仿射流行时取等
-
$\Pi$ 是非扩张映射, $|\Pi_{C}[y]-\Pi_{C}[z] \leq|y-z|$ - 投影映射本身可能很难求
投影下的迭代格式:
\[x^{(k+1)}=\Pi[x^{(k)}+\alpha_{k}d^{(k)}]\]投影梯度法:
\[x^{(k+1)}=\Pi[x^{(k)}-\alpha_{k}\nabla f(x^{(k)})]\]- 仿射约束集 $\Omega={x:Ax=b}$ 上的投影梯度法产生的迭代点满足 $f(x^{(k+1)})<f(x^{(k)})$
- 线性规划使用投影梯度法, 只要步长足够大, 一步就能得到最优解
Lagrange 法
\[\begin{aligned} \mathrm{minimize}\;\;&f(x)\\ \mathrm{subject\ to}\;\;&h_i(x)=0,&i=1,\cdots,m\\ \end{aligned}\]Lagrange 函数:
\[l(x,\lambda)= f(x)+\lambda^{\mathsf{T} }h(x)\]使用梯度法, 每步关于 $x$ 极小化, 关于 $\lambda$ 极大化:
\[\begin{aligned} x^{(k+1)}&=x^{(k)}-\alpha_{k}(\nabla f(x^{(k)})+D h(x^{(k)})^{\top}\lambda^{(k)})\\ \lambda^{(k+1)}&=\lambda^{(k)}+\beta_{k}h(x^{(k)}) \end{aligned}\]对于不等式约束的情况
\[\begin{aligned} \mathrm{minimize}\;\;&f(x)\\ \mathrm{subject\ to}\;\;&g_i(x)\leq0,&i=1,\cdots,m\\ \end{aligned}\]Lagrange 函数:
\[l(x,\mu)={f}(\alpha)+\mu^{\top}g(x)\]使用梯度法关于 $x$ 极小化, 投影梯度法关于 $\mu$ 极大化
\[\begin{aligned} x^{(k+1)}&=x^{(k)}-\alpha_{k}(\nabla f(x^{(k)})+D g(x^{(k)})^{\top}\mu^{(k)})\\ \mu^{(k+1)}&=[\mu^{(k)}+\beta_{k}g(x^{(k)})]_+ \end{aligned}\]罚函数法
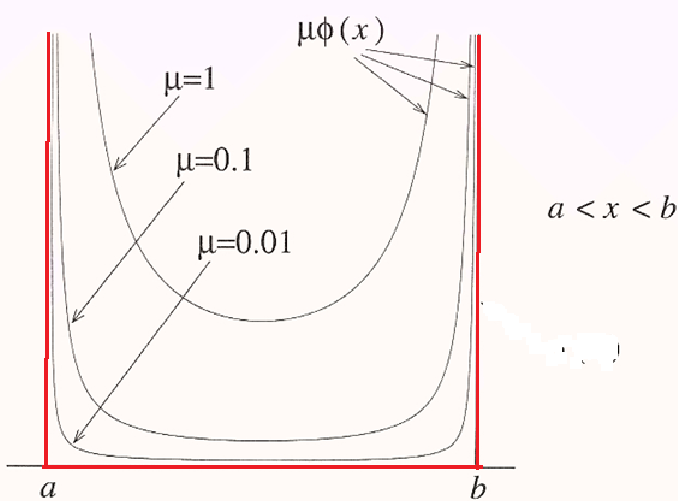
\[\begin{array}{l l}{ {\mathrm{minimize~} } }&{ {f(\alpha)} }\\ { {\mathrm{subject~to} } }&{ {\alpha\in\Omega} }\end{array} \lrArr \mathrm{minimize}\;\;f(x){+}l_{\Omega}(x) \approx \mathrm{minimize}\;\;f(x)+\gamma P(x), \gamma>0\]指示函数
\[l_\Omega(x):= \begin{cases} 0, &x\in\Omega\\ +\infty, &x\notin\Omega \end{cases}\]$P$ 是罚函数, 需满足
- 连续
- $\forall x\in\R^n,P(x)\geq0$
- $P(x)=0\lrArr x\in\Omega$
罚参数 $\gamma$ 越大, 则逼近程度越好.


增广 Lagrange 函数
把 Lagrange 函数与罚函数结合,解决罚参数过大问题