最优化算法速通 - 线搜索
06 December 2022 |
duanyll | Tags:
最优化
在区间 $[a_0, b_0]$ 上求一元单值函数的极小值点.
区间压缩方法
黄金分割法
要求目标函数是单峰的.
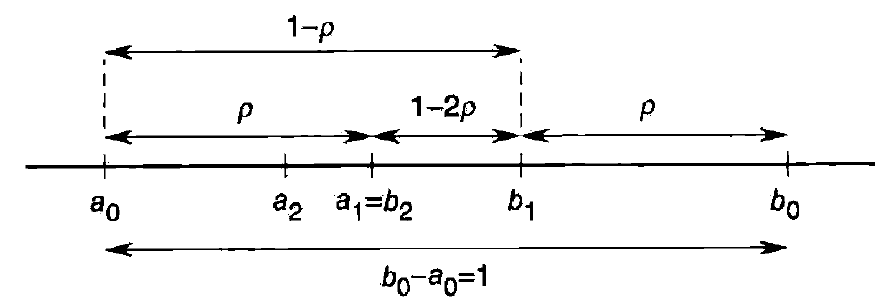
确定合适的参数 $\rho$ 使得每次迭代只需计算一次函数 $f$ 的值. 每一步只需要确定一个新点并计算一次目标函数的值(第1 步除外)。
\[\rho=\frac{3-\sqrt{5} }{2}\approx0.382\]goldenSearch[fun_, var_, l0_, r0_, delta_] :=
Module[{f, a, b, fa, fb, l, r, \[Rho], n}, (
f[x_] = N[fun /. var -> x, precision];
\[Rho] = 2 - GoldenRatio;
l[1] = l0;
r[1] = r0;
a[n_] = l[n] + \[Rho] (r[n] - l[n]);
b[n_] = l[n] + (1 - \[Rho]) (r[n] - l[n]);
fa[n_] = f[a[n]];
fb[n_] = f[b[n]];
n = 1;
While[r[n] - l[n] > delta,
If[fa[n] > fb[n], (
l[n + 1] = a[n];
r[n + 1] = r[n]
), (
l[n + 1] = l[n];
r[n + 1] = b[n]
)
];
n++;
];
Print[
TableForm[
Table[{a[i], b[i], fa[i], fb[i],
Interval[{l[i + 1], r[i + 1]}]}, {i, 1, n - 1}],
TableHeadings -> {Range[n - 1], {"a", "b", "f(a)", "f(b)",
"Next Interval"} }]];
Return[{l[n], r[n]}];
)];
总压缩比: 0.618, 经过 $N$ 步压缩之后,极小点所在区间长度将压缩到初始区间长度的 $(1-\rho)^{N}\approx(0.61803)^{N}$
Fibonacci 数列法
要求目标函数是单峰的.
仍然要求每次压缩区间能利用之前的取值, 希望允许每次迭代的压缩比改变, 使得固定步数的总压缩比最小, 则应使用 Fibonacci 数列的形式设置每步的压缩比.

满足下式时能利用之前的取值:
\[{\rho}_{k+1}(1-{\rho}_{k})=1-2{\rho}_{k}\]即
\[\rho_{k+1}=1-{\frac{\rho_{k} }{1-\rho_{k} } }\]总压缩比: $(1-\rho_{1})(1-\rho_{2})\cdot\cdot\cdot(1-\rho_{N})$
视作有约束优化问题求解, 得到
\[\begin{array}{c}{ {\rho_{1}=1-{\frac{F_{N} }{F_{N+1} } } } }\\ { {\rho_{2}=1-{\frac{F_{N-1} }{F_{N} } } } }\\ \vdots \\{ { {\rho_{k} }=1-{\frac{F_{N-k+1} }{F_{N} } } } }\\ \vdots\\{ {\rho_{N}=1-{\frac{F_{1} }{F_{2} } } } }\end{array}\]注: $F_0=F_1=1,F_n=F_{n-2}+F_{n-1}, n \geq 2$. 总压缩比:
\[(1-\rho_{1})(1-\rho_{2})\cdot\cdot\cdot(1-\rho_{N})={\frac{F_{N} }{F_{N+1} } }{\frac{F_{N-1} }{F_{N} } }\cdots{\frac{F_{1} }{F_{2} } }={\frac{F_{1} }{F_{N+1} } }={\frac{1}{F_{N+1} } }\]注意最后一次迭代 ${\rho_{N}=1-{\frac{F_{1} }{F_{2} } } }=\frac{1}{2}$, 为了保证能产生两个不同的新点以便后续处理, 可取 $\rho_{N}=1/2-\varepsilon$, 总压缩比变为 $\frac{1+2\varepsilon}{F_{N+1} }$
fibonacciSearch[fun_, var_, l0_, r0_, delta_] :=
Module[{f, a, b, fa, fb, l, r, \[Rho], \[Epsilon], n, i}, (
f[x_] = N[fun /. var -> x, precision];
\[Epsilon] = delta/10;
n = 0;
While[(1 + 2 \[Epsilon])/Fibonacci[n + 2] > delta/(r0 - l0), n++];
l[1] = l0;
r[1] = r0;
\[Rho][i_] =
If[i == n, 1/2 - \[Epsilon],
1 - Fibonacci[n + 2 - i]/Fibonacci[n + 3 - i]];
a[i_] = l[i] + \[Rho][i] (r[i] - l[i]);
b[i_] = l[i] + (1 - \[Rho][i]) (r[i] - l[i]);
fa[i_] = f[a[i]];
fb[i_] = f[b[i]];
Do[
If[fa[i] > fb[i], (
l[i + 1] = a[i];
r[i + 1] = r[i]
), (
l[i + 1] = l[i];
r[i + 1] = b[i]
)
],
{i, n}
];
Print[
TableForm[
Table[{\[Rho][i], a[i], b[i], fa[i], fb[i],
Interval[{l[i + 1], r[i + 1]}]}, {i, 1, n}],
TableHeadings -> {Range[n], {"\[Rho]", "a", "b", "f(a)", "f(b)",
"Next Interval"} }]];
Return[{l[n + 1], r[n + 1]}];
)];
二分法
要求目标函数是单峰的, 且一阶可导. 二分找到一阶导数的零点. 总压缩比为 $(1/2)^{N}$, 优于以上两种.
插值类方法
牛顿法
要求目标函数二阶可导. 构造经过 $(x^{(k)},f(x^{(k)})$ 的二次函数, 使得此处一阶导数和二阶导数相同.
二阶 Taylor 逼近:
\[q(x)=f(x^{(k)})+f^{\prime}(x^{(k)})(x-x^{(k)})+{\frac{1}{2} }f^{\prime\prime}(x^{(k)})(x-x^{(k)})^{2}\]$q$ 的极小点:
\[0=q^{\prime}(x)=f^{\prime}(x^{(k)})+f^{\prime\prime}(x^{(k)})(x-x^{(k)})\]则得到迭代公式:
\[x^{(k+1)}=x^{(k)}-{\frac{f^{\prime}(x^{(k)})}{f^{\prime\prime}(x^{(k)})} }\]牛顿法要求 $f^{\prime\prime}(x)>0$ 在区间内成立, 否则可能收敛到极大点. 牛顿法也可以用来求 $g(x)=0$:
\[x^{(k+1)}=x^{(k)}-{\frac{g(x^{(k)})}{g^{\prime}(x^{(k)})} }\]割线法
若目标函数二阶不可导而仅仅一阶可导, 用前两次迭代点的割线代替二次导数:
\[f^{\prime\prime}(x^{(k)})=\frac{f^{\prime}(x^{(k)})-f^{\prime}(x^{(k-1)})}{x^{(k)}-x^{(k-1)} }\]得到迭代公式:
\[x^{(k+1)}=x^{(k)}-{\frac{x^{(k)}-x^{(k-1)} }{f^{\prime}(x^{(k)})-f^{\prime}(x^{(k-1)})} }f^{\prime}(x^{(k)})={\frac{f^{\prime}(x^{(k)})x^{(k-1)}-f^{\prime}(x^{(k-1)})x^{(k)} }{f^{\prime}(x^{(k)})-f^{\prime}(x^{(k-1)})} }\]若用于求根, 减少一次导数:
\[x^{(k+1)}=x^{(k)}-{\frac{x^{(k)}-x^{(k-1)} }{g(x^{(k)})-g(x^{(k-1)})} }g(x^{(k)})={\frac{g(x^{(k)})x^{(k-1)}-g(x^{(k-1)})x^{(k)} }{g(x^{(k)})-g(x^{(k-1)})} }\]通用的插值方法
二次插值: 从一个点或多个点的原函数值, 一阶导数, 二阶导数中选择三个, 可确定一个二次函数拟合, 用二次函数的极值点来产生下一次迭代点. 牛顿法利用了一点的函数值, 一阶导数, 二阶导数; 割线法利用了两点函数值和一阶导数 (多余了)
三次插值则需要找到四个参数.
划界法
寻找目标函数极小点所在的初始区间. 只需要找出3 个点 $a<c<b$ , 使得 函数值满足 $f(c)<f(a)$ 和 $f(c)<f(b)$
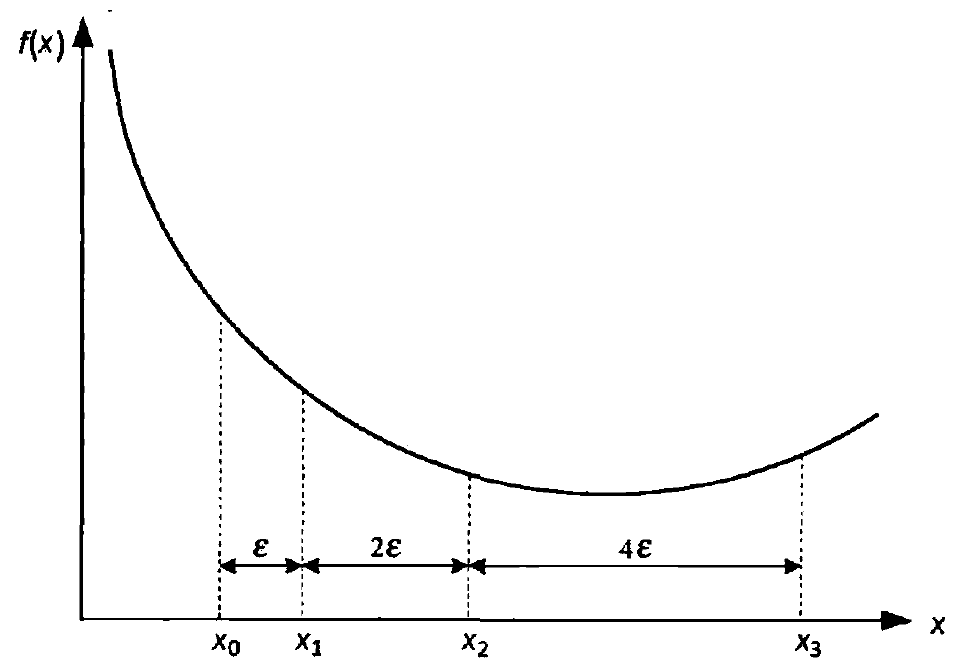

选择 $x_3$ 时可以如图不断向后倍增搜索.
多元函数极小值
函数 $f\colon\mathbb{R}^{n}\to\mathbb{R}$
\[\alpha^{(k+1)}=\alpha^{(k)}+\alpha_{k}d^{(k)}\]$\alpha_k\geq0$ 为步长, $d^{(k)}$ 为搜索方向. 或采用另一种记号, 记 $\alpha_k$ 为步长, $p_k$ 为搜索方向. 希望选取合适的步长和搜索方向, 使得 $\lim_{k\to\infty}|x_k-x^*|=0$
下降方向
一阶 Taylor 展开
\[f(x_{k}+\alpha p_{k}^{*})=f(x_{k})+\alpha p_{k}^{\top}\nabla f(x_{k})+o(\|\alpha p_{k}\|)\]下降方向: $p_{k}^{\top}\nabla f(x_{k}) \lrArr$ $p_k$ 与梯度夹角大于 $\pi/2$
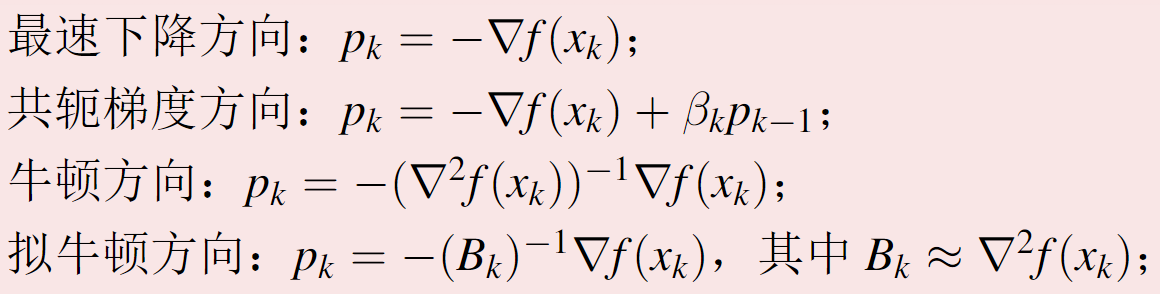
步长选取
精确步长
\[\alpha_k=\arg\min_{\alpha>0}f(x_k+\alpha p_k), \phi(\alpha):=f(x_k+\alpha p_k)\]对于二次函数 $f(x)=\frac{1}{2}x^\top Ax+b^\top x+c$:
\[\alpha=-\frac{p_{k}^{\top}\nabla f(x_{k})}{p_{k}^{\top}A p_{k} }\]非精确步长
使用一些不等式来保证步长的选取比较优秀.
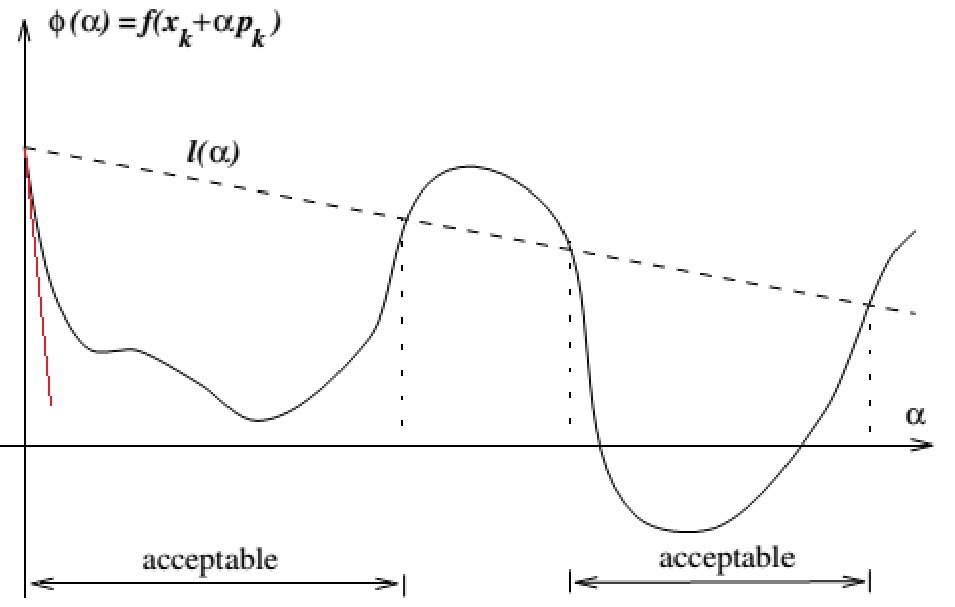
Armijo 准则: 给定参数 $c\in(0,1)$, 通过起点处斜率的倍率划线, 保证下降的程度足够大, 只要 $\alpha$ 足够小总能满足, 公式
\[f(x_{k}+\alpha p_{k})\leq f(x_{k})+c\alpha p_{k}^{\top}\nabla f(x_{k}), c\in(0,1)\]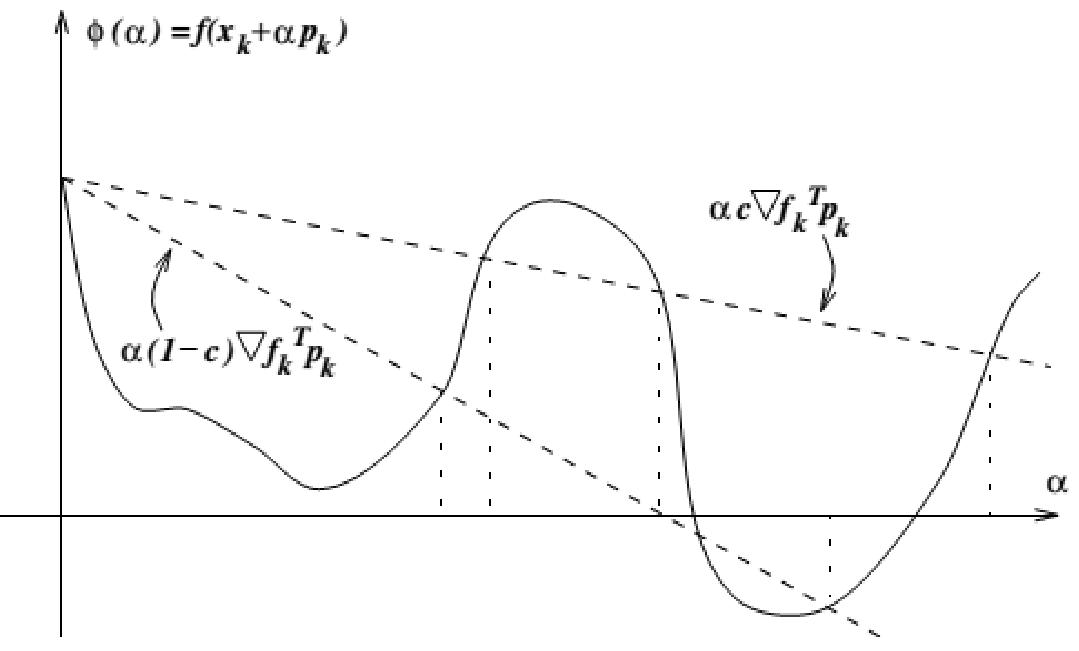
Goldstein 准则: 在 Armijo 的基础上还希望一步能走的尽量远, 再添加限制条件
\[f(x_k+\alpha p_k)\geq f(x_k)+(1-c)\alpha p_k^\top\nabla f(x_k),c\in(0,0.5)\]
Wolfe 准则: 在 Armijo 的基础上, 希望下一次的迭代点处的斜率不要太大, 在这个方向上一步到位, 不要再有微调的机会
\[p_k^\top\nabla f(x_{k+1})\geq c_2p_k^\top\nabla f(x_k), 0<c_1<c_2<1\]